三维图像:体数据
前文所提到如何加载和表示二维图像,在某些情况下,例如设计到ct的医学成像应用程序,我们通常需要处理从头到叫的大量图像序列,每一个序列代表人体的一个切片,ct中只有一个单一的强度通道,类似于灰度通道,这意味着通道维度通常在原生数据格式中被忽略,因此原生数据通常有三个维度
存储体数据的张量和图像没任何区别,在通道维度之后,我们有一个额外的维度,即深度,从而得到一个5维的张量
加载特定格式
使用imageio模块中的volread函数加载一个ct扫描样本,该函数接受将目录作为参数,并将所有医学数字成像和通信文件汇编为一个numpy三维数组
1 | import imageio |
由于没有通道信息,布局与pytorch期望的不同,我们必须使用unsqueeze为通道维度流出空间
1 | vol = torch.from_numpy(vol_arr).float() |
表示表格数据
在机器学习中遇到最简单的数据形式是电子表格,csv文件或者是数据库,无论介质是什么,他都是一张表,每一行包含一个样本或者是记录,其中的列包含关于样本的一部分信息
列可以包含数字,如特定位置的温度或者是标签,以及表示样本属性的字符串,因此,表格数据通常是不是同构的
使用真实的数据集
作为深度学习的实践者,是将真实世界的异构数据编码为浮点数张量,以供神经网络使用,在互联网上我们可以免费或者大量的白哦个数据集,github上有一堆免费开源的数据集
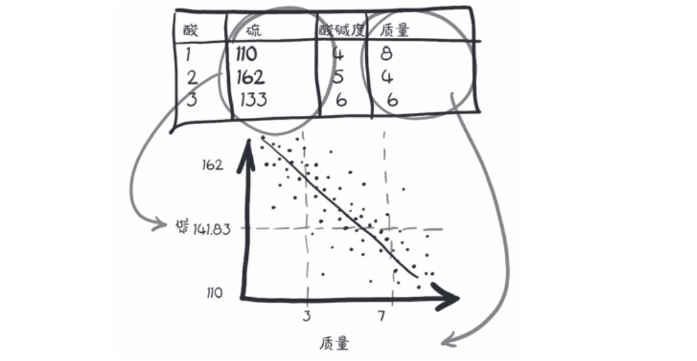
下面举一个例子,葡萄酒的质量数据集是一个免费提供的表格数据集,它包含葡萄牙北部葡萄酒的化学特征以及感官质量评分,可以直接从github上下载
在这个数据集上一个可能的机器学习任务是根据化学特征预测质量评分,如下图所示,我们希望找到数据中化学特征列和质量评分列之间的关系
加载葡萄酒数据张量
我们需要一种比在文本编辑器中打开文件更有用的检查数据的方法,让我们看啊可能如何使用python加载数据,然后将其转化为张量,pytorch提供了几种可选的加载csv文件的方法
1 | ·python自带的csv模块 |
建议使用numpy,pytorch具有出色的numpy互操作性
1 | # 导入csv模块,用于处理CSV文件 |
这里我们之规定了二维数组的类型,用于分割每一行数据的分隔符以及不读取第一行,可以检查一下是否读取了所有的数据
1 | col_list = next(csv.reader(open(wine_path), delimiter=','))#打开指定路径的csv文件,使用reader创建一个csv读取器,设置分隔符为都好,使用next获取文件的第一行,将这些列名存储在变量中 |
继续将numpy数组转化为pytorch张量
1 | wineq = torch.from_numpy(wineq_numpy) |
至此,我们从数据集中获得了一个浮点数的torch.Tensor对象,它包含所有列,也包括表示质量评分的最后一列
表示分数
我们可以将分数视为一个连续变量,把它当作一个实数,然后执行回归任务,或者将其视为一个标签,并尝试在分类任务总根据化学特征分析猜测标签,然后执行回归任务,或者将其视为一个标签,并尝试在分类任务中根据化学特征分析猜测标签,将其保存在单独的张量中,这样就可以将分数作为基本事实而不必将其输入模型中
1 | data = wineq[:, :-1] |
如果想要将target张量转换为标签张量,我们可以有 两种方法,这取决于我们使用分类数据的策略或目的
1 | data = wineq[:, :-1].long() |