表示表格数据
使用独热编码
另一种方法是构建分数的一个独热编码,就是将10个分数分别编码到一个由10个元素组成的向量中,除了其中一个元素设置为1,其他的元素都设置为0,它的主要作用包括:
- 处理分类数据 :将分类特征(如颜色、品牌等)转换为数值形式,使机器学习算法能够处理。
- 避免序数关系 :防止算法错误地解释类别之间存在大小关系。例如,如果将”红、绿、蓝”编码为1、2、3,算法可能会误认为蓝色(3)比红色(1)更重要。
- 增加特征维度 :每个类别变成一个二进制特征,使模型能够学习到每个类别的独立影响。
- 提高模型表达能力 :特别是对于树模型以外的算法(如线性回归、神经网络等),独热编码可以帮助模型更好地学习非线性关系。
如果分数是完全离散的,比如葡萄酒的品种,那么采用独热编码更为合适,因为没有隐含的顺序和距离,独热编码也适用于分数介于整数分数之间的定量分数
我们可以使用scatter_()方法获得一个独热编码,该方法将沿着参数提供的索引方向,将源张量的值填充大输入张量中
1 | target_onebot = torch.zeros(target.shape[0],10) |
如果我们想将分数作为网络的分类输入,就必须将它转化为一个独热编码张量
何时分类
现在已经知道了处理连续数据和分类数据的方法,但是前面有序数据是如何处理的呢,处理这些数据没有通用的方法,最常见的是将这些数据视为分类数据或者连续数据
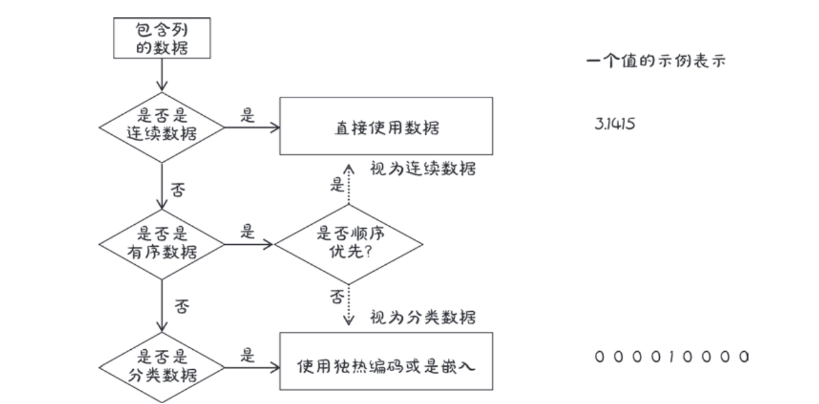
回到张量data,它包含与化学特征分析相关的11个变量,我们可以使用pytorch张量api中的函数来处理张量表格数据,让我们首先获得每一列的平均值和标准差
1 | data_mean = torch.mean(data, dim=0) |
我们还可以通过减去平均值并除以标准差来对数据进行归一化,这有助于我们的学习过程
1 | data_normalized = (data - data_mean) / torch.sqrt(data_var) |
寻找阈值
接下来,让我们分析数据,看看是否有一种简单的方法可以快速分辨出好酒和劣质酒,首先,我们要确定target中哪些行对应的分数小于或者等于3
1 | bad_indexes = target <= 3 |
只有10个bad_indexs记录项被设置为True,通过使用pytorch中高级索引的功能,我们可以使用数据类型torch.bool来索引张量data,这实际上是在过滤张量data,使其仅仅包含索引张量中与True对应的项或者行,张量bad_ubdexs与张量target具有相同的形状,其值为True或者是False取决于我们的阈值与原始张量target的比较结果
1 | bad_data = data[bad_indexes] |
新的张量bad_data有10行,与张量bad_indexes中true的函数相等,它保留了所有列,现在开始我们可以把葡萄酒分为好酒,中等酒和劣质酒3类,让我们对每一行使用mean()函数
1 | 实现了根据红酒质量评分将数据分组,并计算各组特征的平均值,最后以格式化方式打印比较结果 |
这里能发现一些问题,劣质葡萄酒的二氧化硫的含量似乎更高,我们可以使用二氧化硫的总量的阈值来作为区分好酒和劣质酒的粗略标准,让我们看看二氧化硫总量低于我们之前计算的平均值的索引
1 | total_sulfur_threshold = 141.83 |
接下来,我们需要得到真正好酒的索引
1 | actual_indexes = target > 5 |
实际上的优质葡萄酒要比通过阈值测出的数量多,大概700瓶,现在我们看啊可能我们的预测和实际排名是否相符
1 | n_matches = torch.sum(actual_indexes & predicted_indexes).item() |
预测正确855瓶,53%概率可以预测一瓶酒是好酒,识别出了所有的好酒,这个模型确实是高质量的,得到我们所预期的了,但是这跟随机说实话差不了多少,实际情况葡萄酒的质量不只是有这些因素决定的
在后面的简单的神经网络就可以客服这些限制,就像许多其他的基本的机器学习的方法一样,后面也会之间构建自己的第一个神经网络