处理时间序列
处理时间序列,前面用到的葡萄酒的数据集就用不了了,那我们转向另一个数据集,自行车共享系统的数据集,来自华盛顿特区的,目标是将一个平面的二维数据集转换为三维数据集
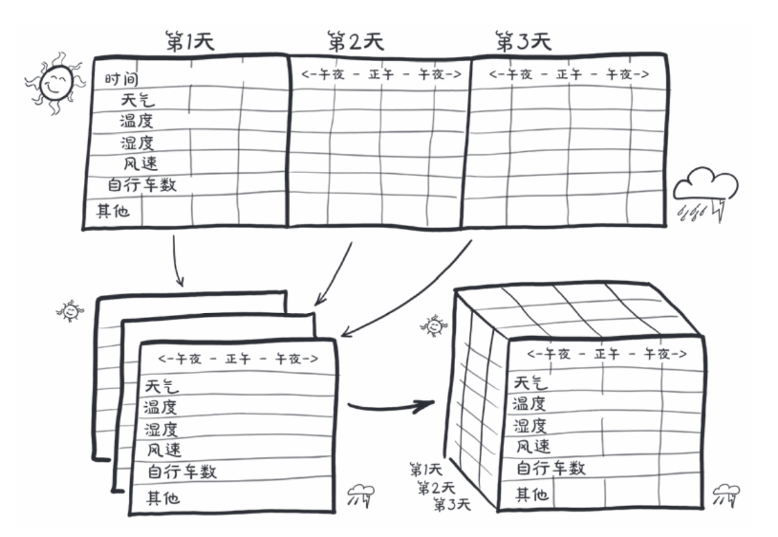
增加一个时间维度
在源数据中,每一行都是一个单独的时间数据,我们需要改变以每一个小时为行的数据组织的方式
1 | # 先查看CSV文件的前几行来了解格式 |
1 | 数据集统计了以下信息。 |
在这样的时间序列数据集中,行表示连续的时间点,有一个维度可以他们对他们进行排序,可以试着根据一天中的某一个时间段来预测自行车的数量,这个就是后面的内容了,暂时不深究,目前专注于学习将共享单车的数据集转换为神经网络能够消化的固定大小的数据块
这个神经网络需要知道每一个不同信息量的一系列的值,例如乘车次数,当日时间,温度和天气等,N个大小为C的对比序列,其中在神经网络的标准中,C代表通道,和一维数据的列一样,N维代表时间轴
按照时间段来调整数据
我们可能想要将2年的数据集分成更细的观察周期,如按天划分,这两我们就有了序列长度为L,样本数量为N的集合C,我们的时间序列数据集将是一个维度为3,形状为NxCxL的张量
回到数据集,为了获得每一个小时的数据集,我们需要做的就是以24个小时为单位来查看同一个张量,让我们看看bikes张量的形状和步长
1 | torch.Size([10886, 12]) (12, 1) |
有10886个小时,12列,现在我们重新调整数据,让它有3个轴,即日,小时
1 | # -1: 自动计算天数(总行数除以24) |
关键是对view的调用,他会改变张量查看存储的相同数据的方法,最右边的维度是原始数据集中的列数,然后中间的维度是时间,将其分割成为连续的24小时,我们需要转置张量:
1 | daily_bikes = daily_bikes.transpose(1, 2) # 交换维度,方便后续分析 |
准备训练
天气状态变量是有序的,它有四个级别,1表示晴天,4表示大雨/大学,我们可以讲这个变量视为分类变量,将级别解释为标签,或者看成连续变量
为了更容易呈现数据,我们暂时只关注第一天的数据,我们初始化一个0填充矩阵,其行数等于一天中的小时数,列数等于天气情况级别数
1 | first_day = bikes[:24].long() |
然后根据每行对应的级别将1散置到矩阵中,
1 | # 使用scatter_函数进行独热编码转换 |
最后我们使用cat函数将矩阵连接到原始数据集,让我们看看第一个结果
1 | # 将原始数据和独热编码后的天气数据拼接在一起,并显示第一个小时的所有特征 |
在这里我们指定了原始张量bikes,以及沿着列连接的独热编码的天气状况矩阵,为了使cat成功。张量必须在其他的维度上具有相同的大小